(Python) Confluence의 모든 페이지 첨부 파일 다운로드 스크립트
Confluence API를 이용하여 모든 페이지의 첨부파일을 다운로드하는 스크립트입니다.
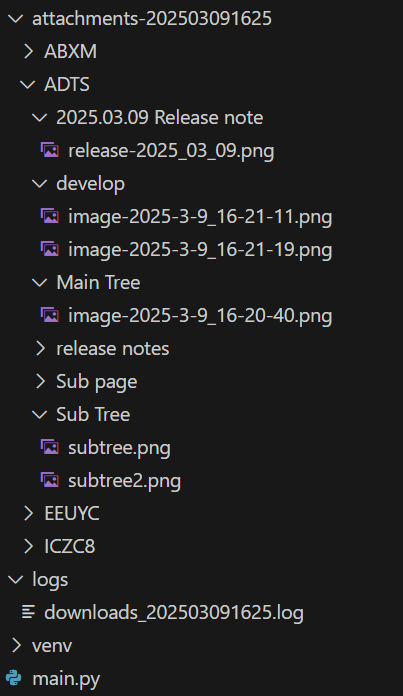
첨부 파일은 페이지별로 디렉토리를 생성하여 저장하며, 파일명에 '/' 문자가 포함되어 있을 경우 '_'로 대체합니다.
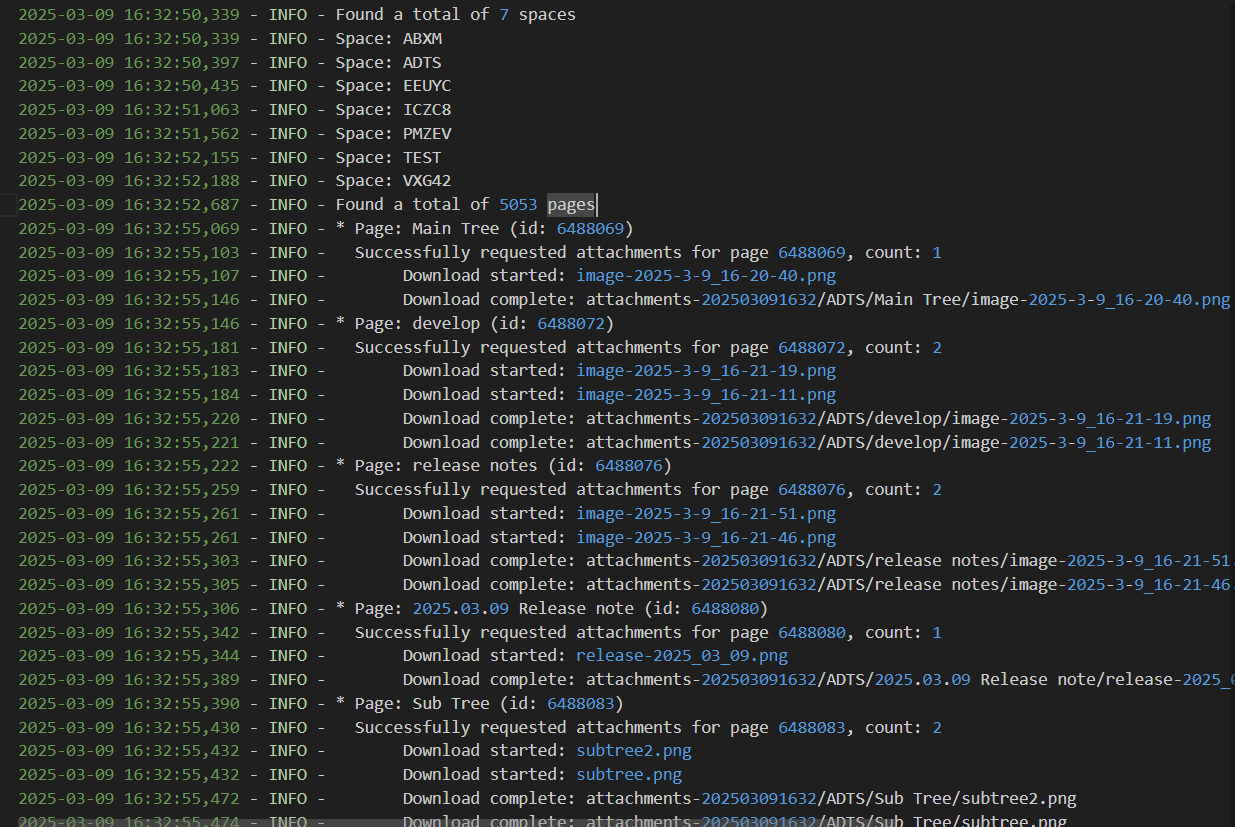
다운로드 로그는 logs 디렉토리에 저장되며, 파일명은 downloads_{현재시간}.log 형식으로 저장됩니다.
다운로드된 첨부 파일은 attachments-{현재 날짜 및 시간} 디렉토리에 저장됩니다.
⚠️
권한이 없는 페이지는 다운로드 되지 않습니다.
Preview

python code
파일 이름은 main.py입니다.
import os
import requests
import logging
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor
import sys
# Define the base URL and token
BASE_URL = "" # Example: https://confluence.example.com
TOKEN = "" # Personal Access Token(https://confluence.example.com/plugins/personalaccesstokens/usertokens.action)
JSON_HEADERS = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {TOKEN}"
}
# Set the current time
now_time = datetime.now().strftime('%Y%m%d%H%M')
# Log file name
log_dir = "logs"
os.makedirs(log_dir, exist_ok=True)
log_filename = os.path.join(log_dir, f"downloads_{now_time}.log")
# Set the log configuration
logging.basicConfig(
filename=log_filename, level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
)
def get_spaces():
url = f"{BASE_URL}/rest/api/space?limit=500"
response = requests.get(url, headers=JSON_HEADERS)
response.raise_for_status()
return response.json().get("results", [])
def get_pages(space_key):
pages = []
start = 0
limit = 500
while True:
url = f"{BASE_URL}/rest/api/content?type=page&spaceKey={space_key}&limit={limit}&start={start}"
response = requests.get(url, headers=JSON_HEADERS)
response.raise_for_status()
data = response.json()
results = data.get("results", [])
pages.extend(results)
if "_links" in data and "next" in data["_links"]:
start += limit
else:
break
return pages
def get_attachments(page_id):
attachments = []
start = 0
limit = 500
while True:
url = f"{BASE_URL}/rest/api/content/{page_id}/child/attachment?limit={limit}&start={start}"
response = requests.get(url, headers=JSON_HEADERS)
if response.status_code != 200:
logging.warning(f" Failed to request attachments for page {page_id}: {response.status_code}")
return []
data = response.json()
results = data.get("results", [])
logging.info(f" Successfully requested attachments for page {page_id}, count: {len(results)}")
if not results:
logging.info(f" No attachments found for page {page_id}")
return []
attachments.extend(results)
if "_links" in data and "next" in data["_links"]:
start += limit
else:
break
return attachments
def download_file(args):
url, save_path, total_downloads = args
response = requests.get(url, headers=JSON_HEADERS, stream=True)
response.raise_for_status()
with open(save_path, "wb") as file:
for chunk in response.iter_content(chunk_size=65536): # 64KB chunk
file.write(chunk)
logging.info(f" Download complete: {save_path}")
total_downloads.append(1)
def process_attachments(space_key, page_title, page_id, total_downloads, current_page, total_pages):
print(f"SPACE: {space_key} downloading... ({current_page}/{total_pages})", end="\r")
attachments = get_attachments(page_id)
if not attachments:
logging.info(f" No attachments")
return
save_dir = os.path.join(f"attachments-{now_time}", space_key, page_title)
os.makedirs(save_dir, exist_ok=True)
tasks = []
for attachment in attachments:
file_name = attachment["title"].replace("/", "_")
file_url = attachment["_links"]["download"]
full_url = f"{BASE_URL}{file_url}"
save_path = os.path.join(save_dir, file_name)
logging.info(f" Download started: {file_name}")
tasks.append((full_url, save_path, total_downloads))
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_file, tasks)
def main():
spaces = get_spaces()
logging.info(f"Found a total of {len(spaces)} spaces")
pages = []
for space in spaces:
space_key = space["key"]
logging.info(f"Space: {space_key}")
space_pages = get_pages(space_key)
pages.extend([(space_key, page) for page in space_pages])
logging.info(f"Found a total of {len(pages)} pages")
total_downloads = []
total_pages = len(pages)
for index, (space_key, page) in enumerate(pages, start=1):
page_id = page["id"]
page_title = page["title"].replace("/", "_")
logging.info(f"* Page: {page_title} (id: {page_id})")
process_attachments(space_key, page_title, page_id, total_downloads, index, total_pages)
print(f"\nA total of {len(total_downloads)} attachments have been downloaded.")
logging.info(f"Total number of downloaded attachments: {len(total_downloads)}")
if __name__ == "__main__":
main()
execute code
pip3 install requests모듈은 requests만 설치하시면 됩니다.
python3 main.py
Member discussion